How We Process 100M+ Products: The AI Behind CommerceFlow
Before LLMs existed, CommerceFlow built custom ML to process 100M+ B2B products. Here's the hybrid AI architecture behind our agents.

How We Process 100M+ Products: The AI Behind CommerceFlow
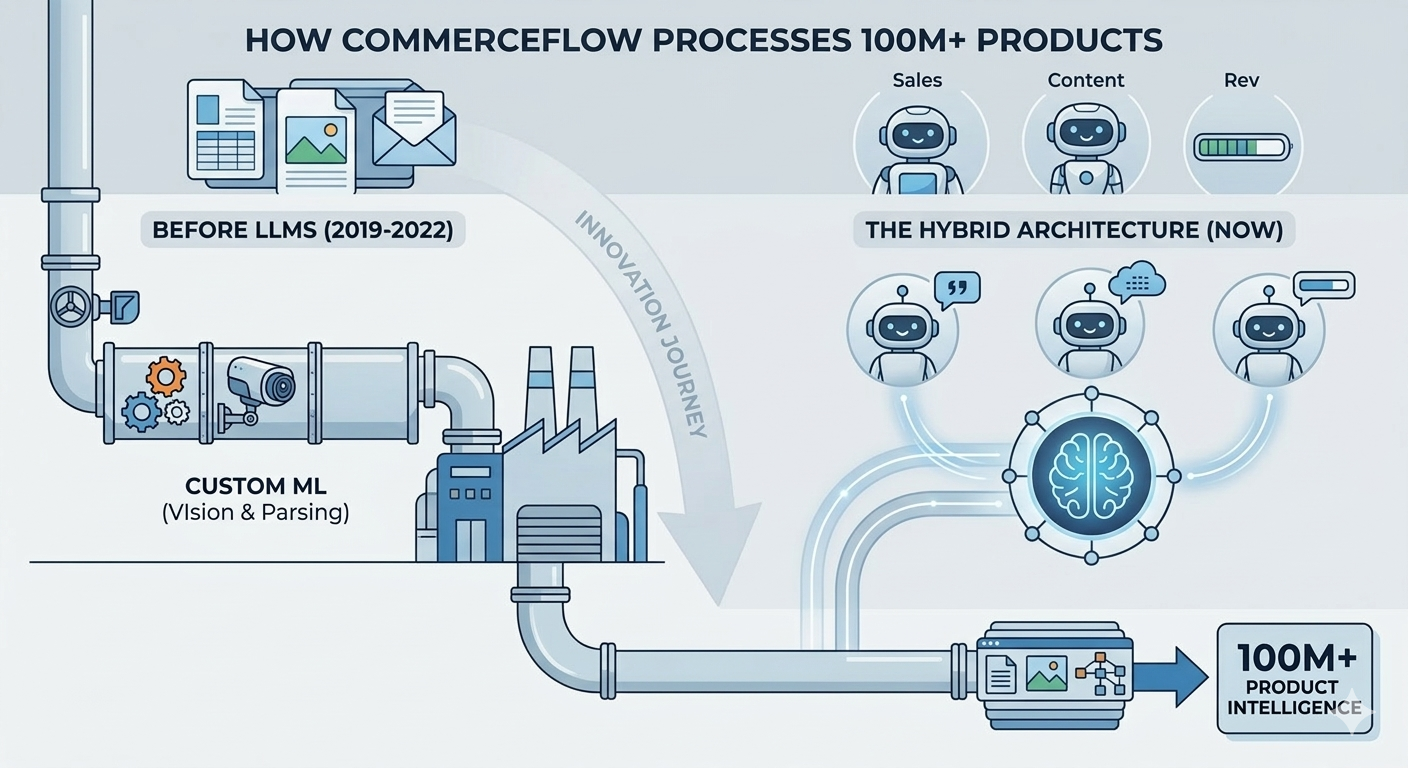
Before Large Language Models, We Built Product Intelligence the Hard Way
In 2019, we faced a problem that seems almost quaint now: we needed to understand 100 million product listings, and nobody had built a system that could do it at scale.
This was before ChatGPT. Before LLMs dominated the AI conversation. Before every startup could bolt a GPT-4 API call onto a spreadsheet and call it "AI."
We couldn't rely on large language models because they didn't exist in production form yet. So we built custom machine learning models to solve the problem we saw happening across every B2B distributor and manufacturer we talked to: product data is everywhere, and nowhere — simultaneously scattered across catalogs, PDFs, images, and spreadsheets; impossible to standardize; critical to getting right.
That journey — from custom ML to modern LLM-augmented agents — is the story of why CommerceFlow works for B2B commerce in ways that generic AI never will.
The Product Data Problem
Walk into any B2B distributor and ask: "Show me all your stainless steel fasteners." What you get back is a spreadsheet with 2,000 SKUs (some accurate, some from a 2015 catalog reboot), a PDF datasheet from the manufacturer with specs in unstructured format, images of product packaging with no metadata, pricing sheets with incomplete attributes, customer feedback buried in email threads, and legacy systems that have different SKUs for the same product.
The human brain is brilliant at synthesizing this chaos. A sales rep with 10 years of experience can answer almost any product question because they've internalized patterns no database documents. But that knowledge is non-transferable — when the rep leaves, the knowledge evaporates. It's non-scalable — it only works if you have enough expert reps. And it's non-intelligent — it's contextual memory, not systematic understanding.
Scaling a B2B business without systematizing product intelligence is like building a house without a foundation. You can grow, but you're constantly one key person away from collapse.
🗂️ Your product data is everywhere — and nowhere. ContentPulse was built to fix exactly that. See how ContentPulse structures 100M+ B2B products into agent-ready catalogs →
The 2019 Solution: Custom Computer Vision
We started with a question: can we automatically extract product attributes from images and documents? The answer was yes — but it required custom-built machine learning models.
Image Recognition Pipeline — Custom CNNs trained on product packaging, technical drawings, and product photography. Not for identification, but for attribute extraction: identifying bolt head type from an image, reading dimension text from product packaging, recognizing material finish from a photograph.
PDF Parsing with OCR + Structure Detection — Standard OCR works poorly on technical documents. We built models to understand document structure — this is a spec table, this is a certification block, this is pricing information — and extract accordingly. We learned to handle poor-quality scans, handwritten notes, and image-based PDFs.
Attribute Mapping & Normalization — Extract "6061-T6 Aluminum Alloy" and map it to internal taxonomy. Extract "1/4-20 UNC" and normalize to standardized SKU naming. Identify equivalent products across different manufacturers and catalogs. Resolve conflicts when the same product has inconsistent data across sources.
Catalog Harmonization — Ingest catalogs from distributors, manufacturers, and competitors. Identify duplicate SKUs across systems. Merge attributes into a unified product graph. Maintain bidirectional links so that equivalent SKUs across different suppliers are connected.
The infrastructure was built on TensorFlow and PyTorch, processing product data from images, PDFs, spreadsheets, and raw text at scale — 100M+ products processed and updated continuously as new data arrived. Distributors who could automatically extract and standardize product data gained 2–3 year advantages over competitors.
The Problem with Pure ML
But custom ML has limitations. Models are data-hungry — training requires thousands of labeled examples, which gets harder for domain-specific tasks. They're subject to domain drift — when catalogs change or new product categories are added, the model needs retraining. They're hard to interpret — when a model extracted wrong data, debugging was guesswork across millions of floating-point weights. And they're brittle — if a PDF format changed or a new manufacturer used different terminology, the model would fail silently.
This meant we were constantly retraining, patching, and maintaining models. It worked, but it was operationally expensive.
The LLM Inflection Point (2023–2024)
Then everything changed. Large language models arrived with capabilities that were transformative for this problem. LLMs could reason over data — reading a messy spec sheet and understanding what it meant, rather than pattern-matching against training data. They supported few-shot learning — instead of retraining a model every time we encountered new product categories, we could show the LLM a few examples and it generalized. They offered multi-modal understanding — handling text, images, and structured data simultaneously. And crucially, they provided explainability — when we ask an LLM why it extracted a particular attribute value, it can explain its reasoning.
📊 Curious how this architecture translates to real revenue results? See what our customers have achieved. Read real results from B2B distributors and manufacturers →
The Hybrid Architecture We Built
Here's what we realized: we shouldn't replace custom ML. We should augment it.
Layer 1: Custom ML for High-Velocity Tasks
Image attribute extraction, document structure detection, and rough attribute classification all run on custom ML. Why? Because these tasks are repetitive and high-volume — 100M+ products, billions of downstream queries. They're standardized — bolt head types don't change; the way we detect them can be optimized. They're latency-sensitive — customers expect real-time queries, not LLM inference delays. And they're cost-sensitive — running LLM inference on 100M products daily would be prohibitively expensive.
Layer 2: LLM-Augmented Reasoning
When raw ML outputs are uncertain or conflicting, when we need to synthesize information from multiple sources, when handling novel product categories or terminologies, and when generating natural language explanations — that's when LLMs step in. These tasks require semantic understanding, reasoning across data types, flexibility for new product categories, and explainability that customers can trust.
Layer 3: Agentic Behavior
Our three agents — SalesPulse, ContentPulse, and RevPulse — sit on top of both Layer 1 and Layer 2. They use ML-extracted attributes for speed and cost efficiency, invoke LLM reasoning for judgment calls, and learn from user interactions to update their behavior over time.
Example — Quote Generation via SalesPulse:
- Incoming request: "50 units of SKU-44928X, delivered by Q2"
- Layer 1 (Custom ML): Retrieve SKU attributes instantly from cached database — material, dimensions, specifications all pre-extracted
- Layer 2 (LLM Reasoning): If the request includes custom specs or exceptions, invoke LLM to determine if substitutes are acceptable
- Layer 3 (Agent): Generate quote, apply pricing rules, flag for approval if necessary
Why This Heritage Matters
1. We Understand Product Data Complexity — We spent years learning how product data actually flows: what's in your ERP (structured, but incomplete), what's in your supplier datasheets (comprehensive, but unstructured), what's in your customer conversations (anecdotal, but revealing), and what's missing entirely — equivalency relationships, substitution rules, historical purchasing patterns. Most teams are 3–4 months into this learning. We're 5 years in.
2. We Can Extract Data from Legacy Systems — You have 50,000 products in your catalog. Some are from a 2005 system migration. Some are images of printed spec sheets. Generic LLMs will hallucinate — confidently inventing attribute values that don't exist. Our hybrid architecture is specifically built to handle this chaos without making things up.
3. We Know the Economics — If we run LLM inference on every product query, costs balloon. Real-time quote requests hit our API thousands of times a day. Our custom ML layer ensures 90% of queries are answered at commodity cost. LLM reasoning is reserved for the 10% that actually need it. That's the difference between a sustainable business and a cost-prohibitive one.
4. We Learn Your Business — Our agents don't just have general knowledge. They learn your pricing structure and what exceptions you allow, your approval workflows and decision thresholds, your product relationships and which substitutes your salespeople actually recommend, your customer patterns, and your competitive position. This knowledge compounds. Every quote, every negotiation, every customer interaction teaches the agents more about how your business actually works. A generic LLM never learns about your business. Our agents do.
The Evolution Continues
Today, we're adding multimodal learning — training models to reason jointly about text, images, and customer behavior data. Real-time personalization — pricing and product recommendations that adapt to individual customer buying patterns. Autonomous negotiation — agents that negotiate pricing and terms within guardrails, learning from historical outcomes. And supply chain intelligence — agents that predict demand and automatically optimize inventory across your network.
All of this sits on the foundation we built: deep understanding of how B2B product data works.
Why You Should Care
When evaluating B2B commerce platforms, you'll encounter three options:
Option A — "We use GPT-4": Cheap to build, expensive to run. Works for obvious tasks, hallucinates on edge cases. No understanding of your specific business. Costs escalate with scale.
Option B — "We built custom ML": Expensive to build, but optimized. Handles your specific data patterns. High technical debt when you need to change. Doesn't adapt when your business evolves.
Option C — "We built a hybrid architecture with 5 years of B2B domain expertise": Optimized for cost at your scale. Learns your specific business patterns. Reasoning layer adapts when your business changes. Designed for enterprises, not startups.
CommerceFlow is Option C. We built it because we couldn't buy it anywhere. We spent three years optimizing the architecture, processing 100M+ products, and training on real B2B transactions. The result isn't just a platform — it's institutional knowledge about how B2B commerce actually works.
The Real Differentiator
Generic AI is trained on public internet data — retail websites, consumer reviews, text databases. It has no idea how custom pricing matrices work, how approval chains function in enterprises, how technical procurement actually happens, or how B2B relationships develop and strengthen.
Our AI is trained on B2B commerce transactions. Thousands of real quotes, negotiations, procurement decisions, and customer relationship patterns. That's the difference between a tool that understands commerce and a tool that understands language.
The distributors and manufacturers that move first will have agents trained on 5+ years of their own transaction data. That's structural competitive advantage. Every month you delay is a month of learning you don't capture.
🏆 Five years of B2B product intelligence. 100M+ products processed. Ready to put it to work for your catalog? Book a 15-minute demo and see CommerceFlow's hybrid AI in action →
CommerceFlow's agents have processed 100M+ products and learned from thousands of B2B transactions. They're not generic AI wrapped around your ERP — they're purpose-built for the complexity of B2B commerce. Talk to our team →